Aufgrund der finanziellen Grundlage des Projekts haben wir uns dazu entschieden mit Machine Learning für das Tracking weiterzuarbeiten. Motiontrackinganzüge oder ähnliche Technologien zu nutzen, wäre in der Skalierung für ein ganzes Orchester viel zu hoch angesetzt. Der finanzielle Aufwand für diese Vielzahl an Material und Technik wäre immens. Außerdem war noch gar nicht wirklich klar, wie die Musiker damit umgehen und wie diese solchen Arbeitsaufwand aufnehmen.
Die Grundlage für ein Tracking durch eine Videoaufnahme geschieht erst einmal zweidimensional. Dem MachineLearning Model wird also ein Video als Input gegeben, welches dann statistisch abgleicht wie viele Personen und Gelenke im Bild sind und wo diese sich befinden. Gearbeitet wurde mit der Openpose Library
https://github.com/CMU-Perceptual-Computing-Lab/openpose
Das Bild oder Video, welches als Input festgelegt wird, erstellt einen statistischen Abgleich anhand des CMU Panoptic Datensatzes (http://domedb.perception.cs.cmu.edu/) mit Struktur des COCO Models, das wie folgt aussieht.
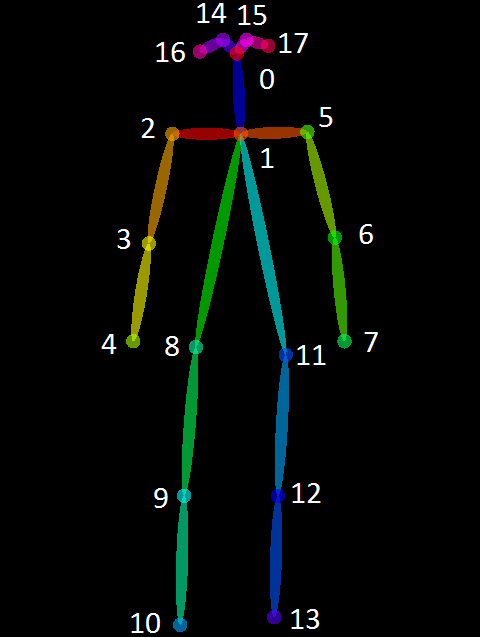
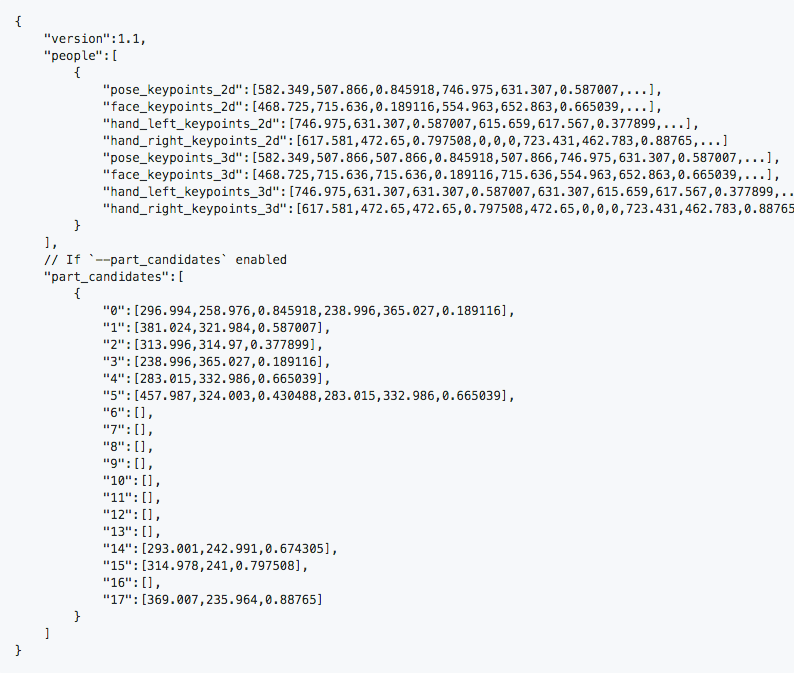
Es werden also die Gelenke/Keypoints erkannt und zu einem humanoiden Skelett zusammengefügt. Der Output is dann selbst definierbar. Man kann das Video mit einem Overlay der erkannten Skelette ausgeben lassen(auf dem Input Video und auf schwarz) und zudem für jeden Frame des Videos eine .json datei in der die x,y und c Werte eines jeden Gelenks notiert werden. Der c-Wert steht für confidence - d.h. wie sicher gibt die Library an, diesen Wert richtig bestimmt zu haben. Die .json Dateien sind also der erste Schritt für eine digitalisierte Bewegung. Anhand des folgenden Bildes ist zu erkennen wie der Output aussieht.

Hier sieht man die Grobstruktur einer .json Datei, die für jeden Frame erstellt wird.
Da eine lokale Installation von Openpose aufwendig ist und die Funktion stark von kleineren Libraries und der Systemkonfiguration abhängt, wurde mit einem Docker Container gearbeitet, in dem man über die Shell aus Linux angesteuert mit der Library arbeiten kann.
Wir haben hier mit dem diesem Docker Image gearbeitet:
https://hub.docker.com/r/wenwu449/openpose
Hier eine kurze Erläuterung der Vorbereitungen, Herangehensweise und der Befehle
Man benötigt:
Installiertes Linux OS (Ubuntu o. ä.)
https://www.ubuntu.com/download/desktop
Installiertes Docker per Shell
https://docs.docker.com/install/linux/docker-ce/ubuntu/#install-docker-ce-1
Installiertes nVidia Docker
https://github.com/NVIDIA/nvidia-docker/wiki/Installation-(version-2.0)
Hier sollten die Treiber und die Grafikkarte nicht zu neu sein, denn nvidia docker hängt zusammen mit der cuda version, welche die Grafikkarte vorgibt.
Genaueres nachzulesen gibt es hier:
https://github.com/NVIDIA/nvidia-docker/wiki/CUDA#requirements
Wenn die Installationen fertig sind können wir damit arbeiten.
sudo nvidia-docker run -v /path/to/directory:/data -it wenwu449/openpose:latest bash
Jetzt sind wir innerhalb der Library.
/path/to/directory:/data
Mit diesem Pfad definieren wir einen lokalen Ordner aus dem Openpose seine Daten zieht. /data wird später zum abgreifen des Pfades.
Der Basisbefehl um ein Video als Input zu definieren und als Output ein Overlay Video mit .json Daten zu generieren lautet:
./build/examples/openpose/openpose.bin --video /data/video.mp4 --display 0 --write_video /data/newvideo.avi --write_keypoint_json /data/
--video legt fest welches video interpretiert werden soll.
--display 0 blendet den Prozess der Erkennung aus
--write_video gibt einen pfad für das Ausgabevideo
--number_people_max 1 sagt maximale Personen zu erkennen auf 1 setzen
--camera_fps 59.94 legt fest mit wie viel fps das ausgabevideo exportiert wird (falls das Inputvideo mehr als 30 fps hat)
Nachdem der Umgang der Library umgänglicher wurde, sind mit selbst erstellten Testvideos die Genauigkeit und die Grenzen erprobt worden.
Was passiert bei einer Verdrehung des Körpers? Wie geht die Library mit verdeckten Gelenken um? Stimmt bei mehreren Personen die Zuordnung der Werte/Koordinaten? Wie wirkt sich Lage der Person und die Position der Kamera auf das Tracking und die Daten aus?
Anhand dieser Tests, konnte recht gut abgeschätzt werden, welche Situation für die Aufnahmen mit den Musikern geschaffen werden sollte. Es wird auch durchaus knifflig alle erstellten Videos der Musiker in einem Stapel mit der Library zu verarbeiten.
Im nächsten Post geht es um die Weiterverarbeitung der 2D Daten.